Part 2 - Story Splitting A Practical Look
(Reading Time: 4 minutes 18 seconds)
Introduction
The first article in this series was an “explain like I’m 5” explanation of story splitting. We are now going to attempt a much more mature version of the same article. The naive approach to story-splitting is thinking of it as a quick thing we can do in a meeting, that takes maybe 5 minutes tops. Split this story, and poof the story is split. The reality is significantly different to have good splits of stories. You have to understand the current codebase, current patterns, and used paradigms within your team. Then, have a meeting that looks a lot more like a design meeting to come to an understanding of what the code should look like. Finally, splitting according to an acronym like SPIDR is possible.
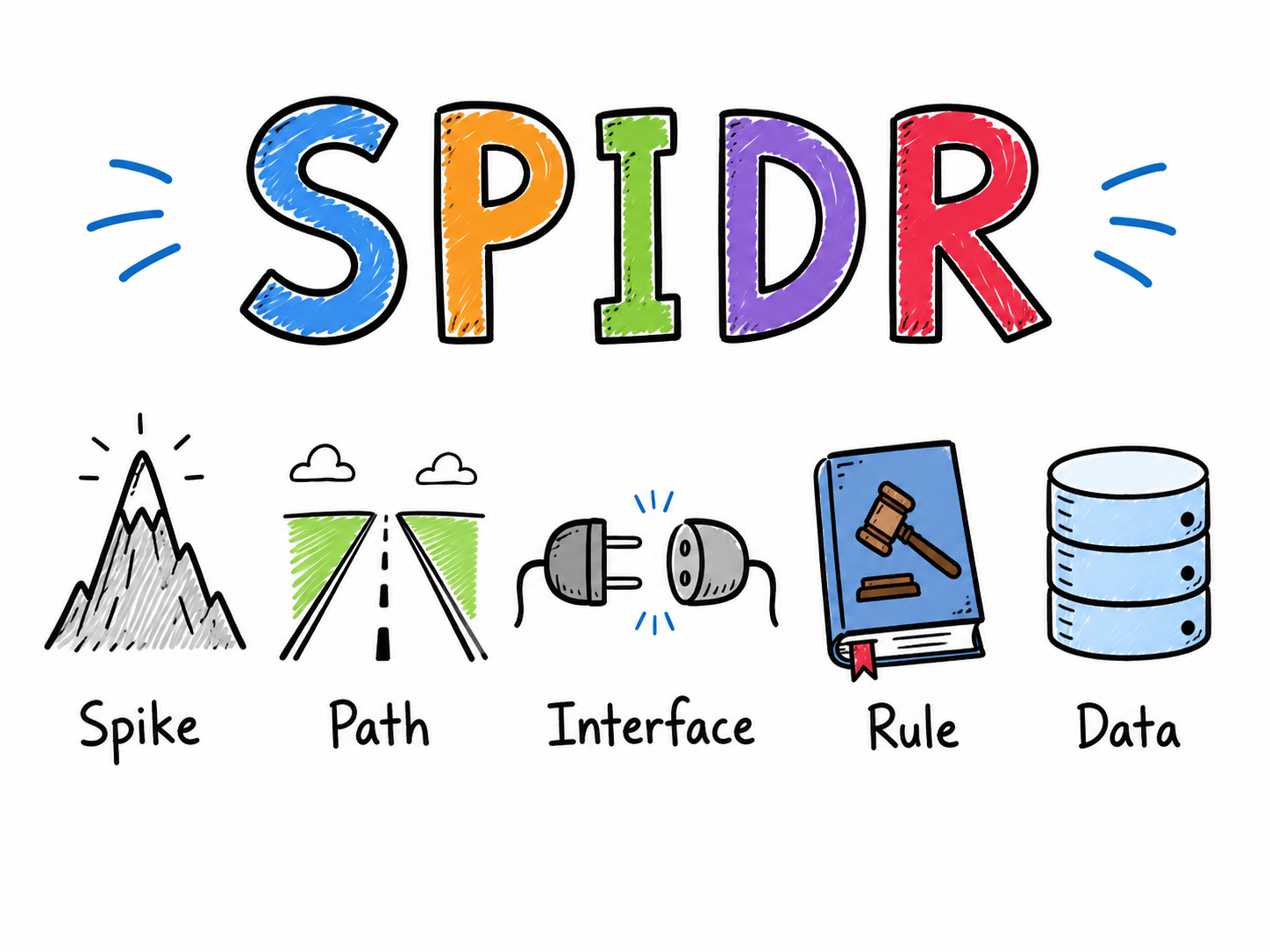
Applying SPIDR to Authentication
Begin by Reframing Authentication with SPIDR
For our old authentication example, we are going to start with attempting SPIDR kind of blindly in our first attempt. We want to write out our epic for the entire authentication flow. After some homework (or maybe just asking chatgpt for a list properly) we come up with the below list:
| SPIDR | Story title | Blocked by |
|---|---|---|
| Spike | Decide the minimum authentication approach | Not blocked |
| Path | Register with email and password | #1 |
| Path | Log in with email and password | #2 |
| Path | Log out of the application | #3 |
| Path | View a protected account page after logging in | #3 |
| Path | Show useful errors for failed registration and login | Partly blocked by #2 and #3 |
| Interface | Keep the browser UI in sync with authentication state | #3 and #4 |
| Interface | Stay logged in across page refreshes | #7 |
| Rule | Prevent unauthenticated access to protected pages | #5 |
| Rule | Reject invalid or expired sessions | #3 and #8 |
Something is off here as well. A lot of the work is sequential. The part we missed is thin vertical slices. Sure, we identified the components within the general epic, but we have failed (yet again) to identify the thin vertical slices. These slices should look iterative, not like a puzzle piece/components.
The SPIDR Fanout
The general SPIDR format is: setup a SPIKE to learn the general formatting, then go through the minimum skeleton path. After we have the skeleton done, we can begin filling in the path with the Interface, Rules, and finally the Data.
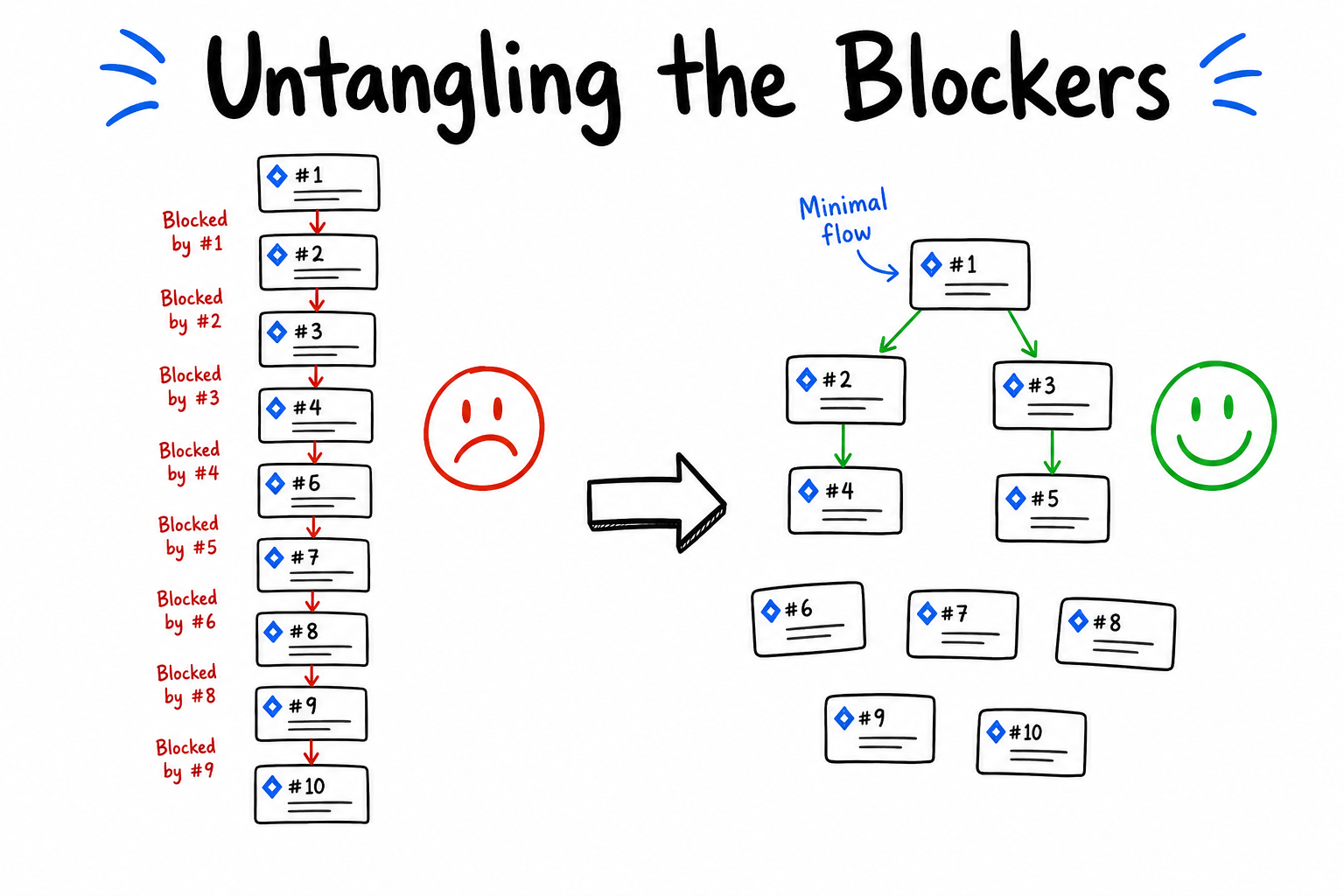
Removing The Blocking Portions to Have Independent Stories
| SPIDR | Story title | Blocked by |
|---|---|---|
| Spike | Decide the minimum authentication approach | Nothing |
| Path | Complete minimal register/login/logout flow | Decide the minimum approach |
| Path | Handle failed registration attempts | Complete minimal flow |
| Path | Handle failed login attempts | Complete minimal flow |
| Interface | Keep browser authentication state correct after refresh | Complete minimal flow |
| Rule | Prevent unauthenticated access to protected pages | Complete minimal flow |
| Rule | Reject invalid or expired sessions | Complete minimal flow |
| Rule | Store passwords securely | Complete minimal flow |
| Rule | Limit repeated failed login attempts | Complete minimal flow |
| Data | Return the current authenticated user’s basic account identity | Complete minimal flow |
Now the only thing that usually blocks us is the first two stories. We need a minimal skeleton built, before we fill in the abbreviated/niave parts.
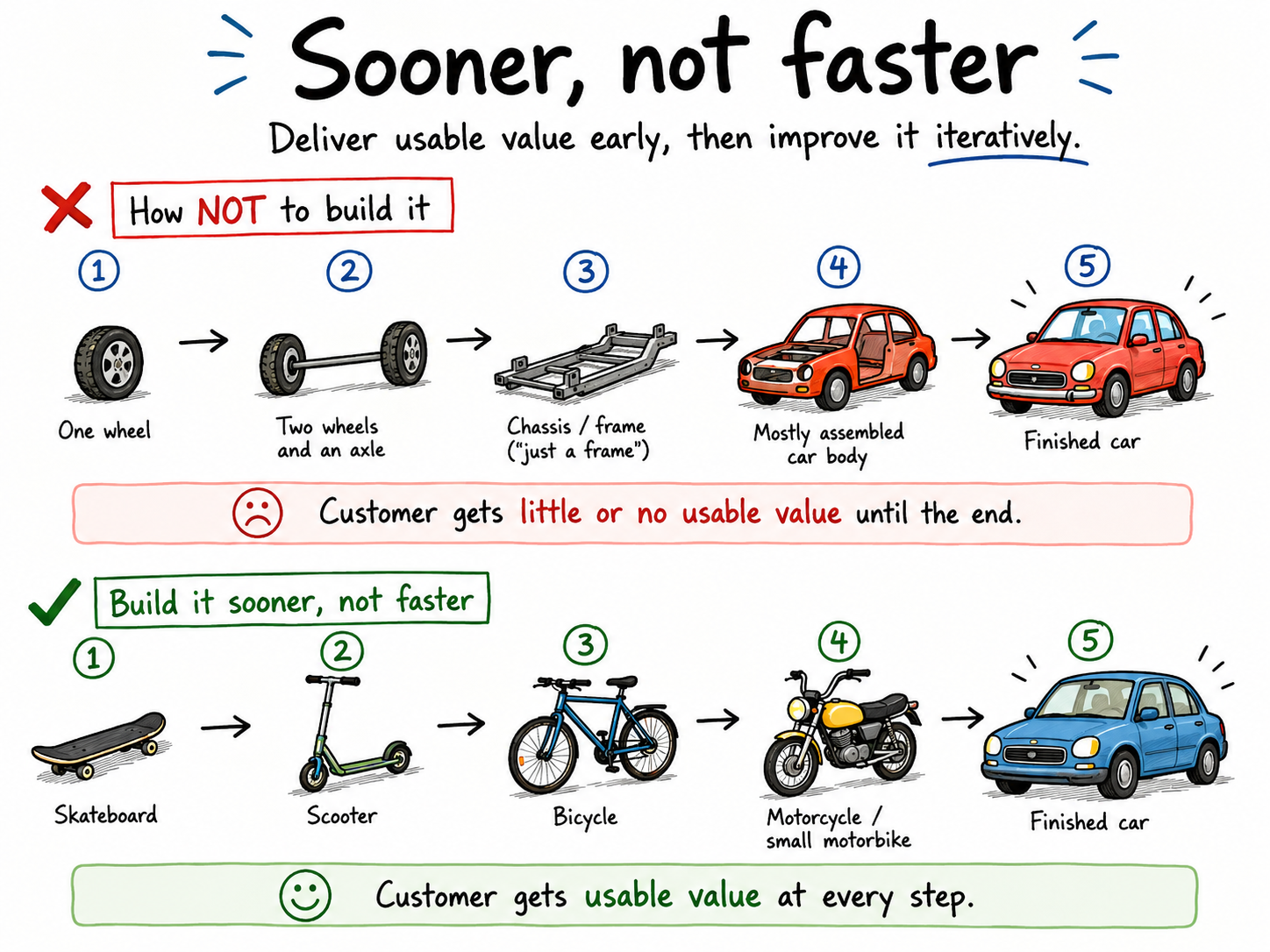
The Agile Core - Sooner not Faster
The general idea here is to deliver sooner, not faster. The way we can deliver the same feature in a shorter period of time is either to just go generally faster (very hard to achieve), or we start doing things like playing with the scope, and iterative development. So with the skeleton approach, we are building out the entire flow in a very brief manner, so that we understand all the pieces of the system in a simplistic and niave manner. Then, we can fill in the blanks of each portion of the authentication flow.
It’s funny, I’ve seen this picture probably a 100 times now, and I feel like now I finally understand it. Chances are, however, that I still don’t understand it (as I’ve gotten it wrong at least 99 times now). But hey, let us take another crack at it. The idea is that while building a transportation vehicle for the client, we have iteratively developed better and better solutions for the same valuable thing your product does. Building a wheel has no value, just like building a pair of wheels also has no value. However, if we first give the customer a skateboard, then a scooter, etc. they will have something useful every time. Think of this in terms of feature development as well. If we think of each component as the car as a simple “feature we must build” we have also accidentally fallen into thinking about what we want in components. Instead, we need to iteratively build a better and better solution to whatever solves the core customer need.
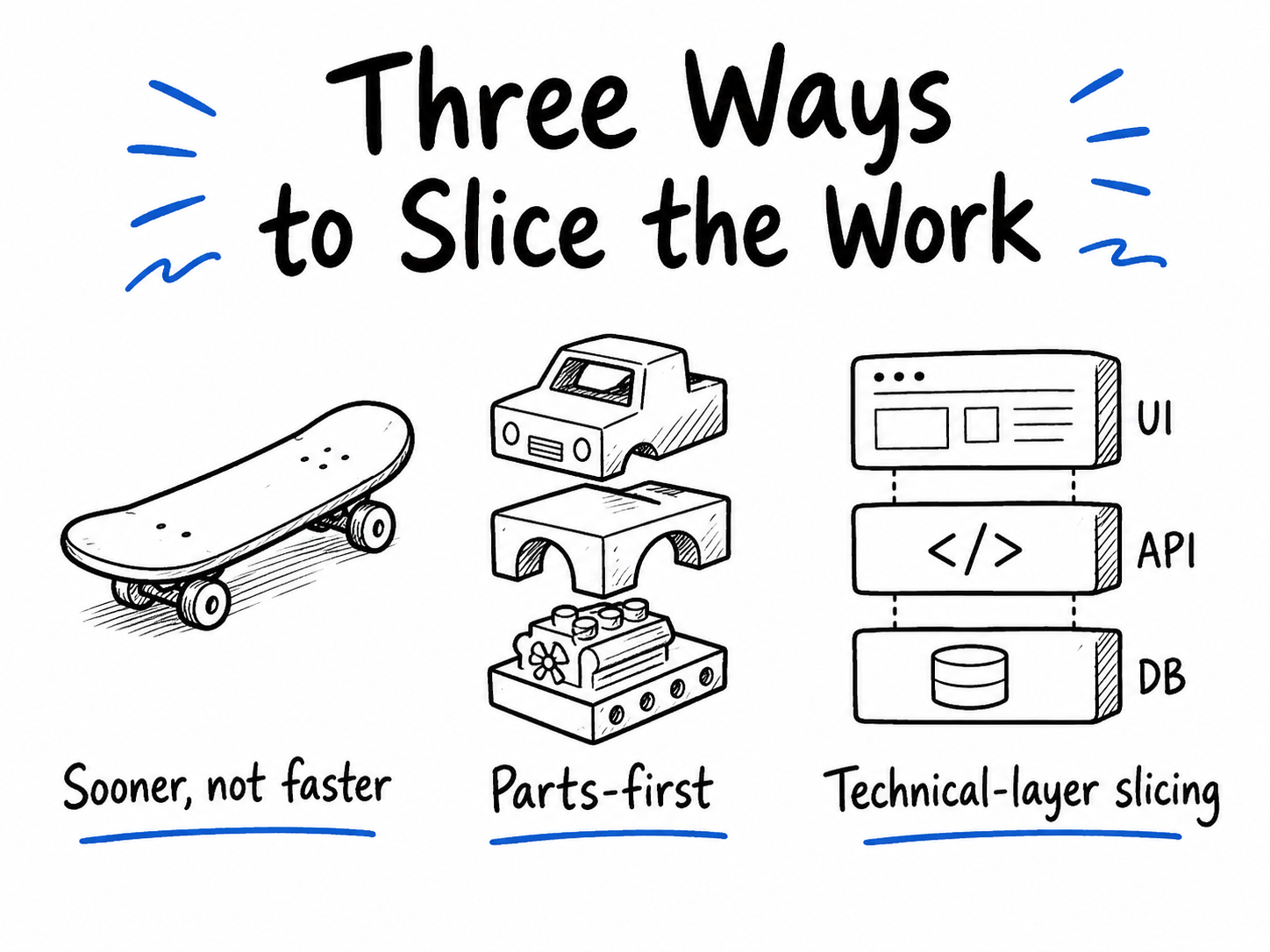
The Agile Core - Build Methods
Actually, there are three different ways we could build this feature. And we may fall into the tradeoffs of one of the three modes below:
| Technique | What it optimizes for | Tradeoff |
|---|---|---|
| Sooner, not faster | Early usable value and feedback | Requires careful slicing |
| Parts-first / component-first | logical construction order | value appears late |
| Technical-layer slicing | architectural separation | integration risk and feedback arrive late |
So yes, sometimes we want to validate our product idea, and in this case sooner, not faster is the ideal build paradigm. However, other-times we just want to show the product owner/team that we are making progress towards some portion of the feature. Parts-first works well in these cases, where they can see the UI being build, API, and then database layers. Finally, we may divide up the work by logical technical boundaries, such as microservices. So we assign a developer to each architecture piece, and give definitions for the interfaces that exist between each code structure (with minimal communication between the microservices).
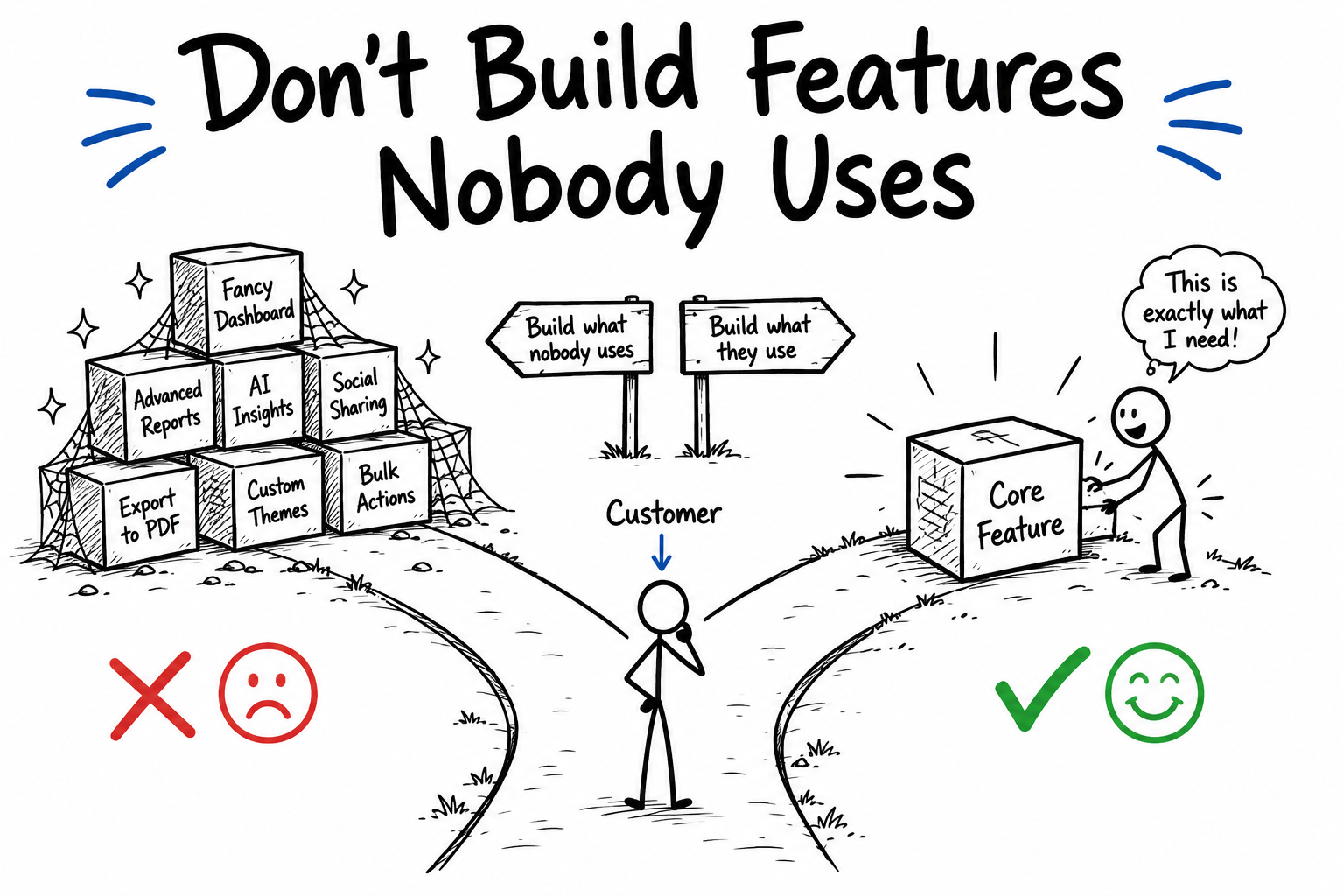
Conclusion - Understand the Product Focus
The key here, is once we have discovered the key need our product solves, we want to iterate on the delivery of this feature to continually give the customer a better experience while using our solution. Don’t just pump out features that noone ever uses, but instead give the customer a stronger value proposition for choosing you over competitors.
References
- http://butunclebob.com/ArticleS.TimOttinger.SoonerNotFaster